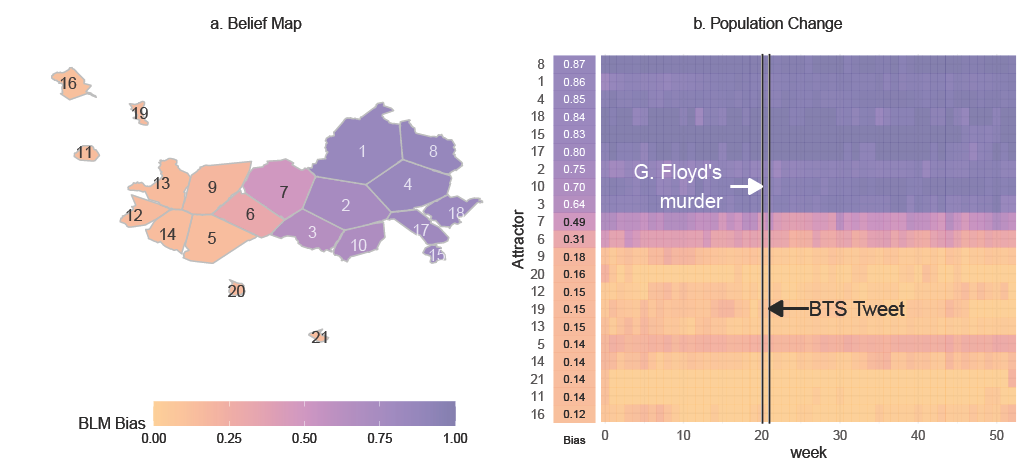
The internet has transformed activism, giving rise to more organic, diverse, and dynamic social movements that transcend geo-political boundaries. Despite extensive research on the role of social media and the internet in cross-cultural activism, the fundamental motivations driving these global movements remain poorly understood. This study examines two plausible explanations for cross-cultural activism: first, that it is driven by influential online opinion leaders, and second, that it results from individuals resonating with emergent sets of beliefs, values, and norms. We conduct a case study of the interaction between K-pop fans and the Black Lives Matter (BLM) movement on Twitter following the murder of George Floyd. Our findings provide strong evidence that belief alignment, where people resonate with common beliefs, is a primary driver of cross-cultural interactions in digital activism. We also demonstrate that while the actions of potential opinion leaders–in this case, K-pop entertainers–may amplify activism and lead to further expressions of love and admiration from fans, they do not appear to be a direct cause of activism. Finally, we report some initial evidence that the interaction between BLM and K-pop led to slight increases in their overall belief similarity.
2025
LLM-Supported Content Analysis of Motivated Reasoning on Climate Change
Yuheun Kim, Qiaoyi Liu, and Jeff Hemsley
Proceedings of the Association for Information Science and Technology 2025
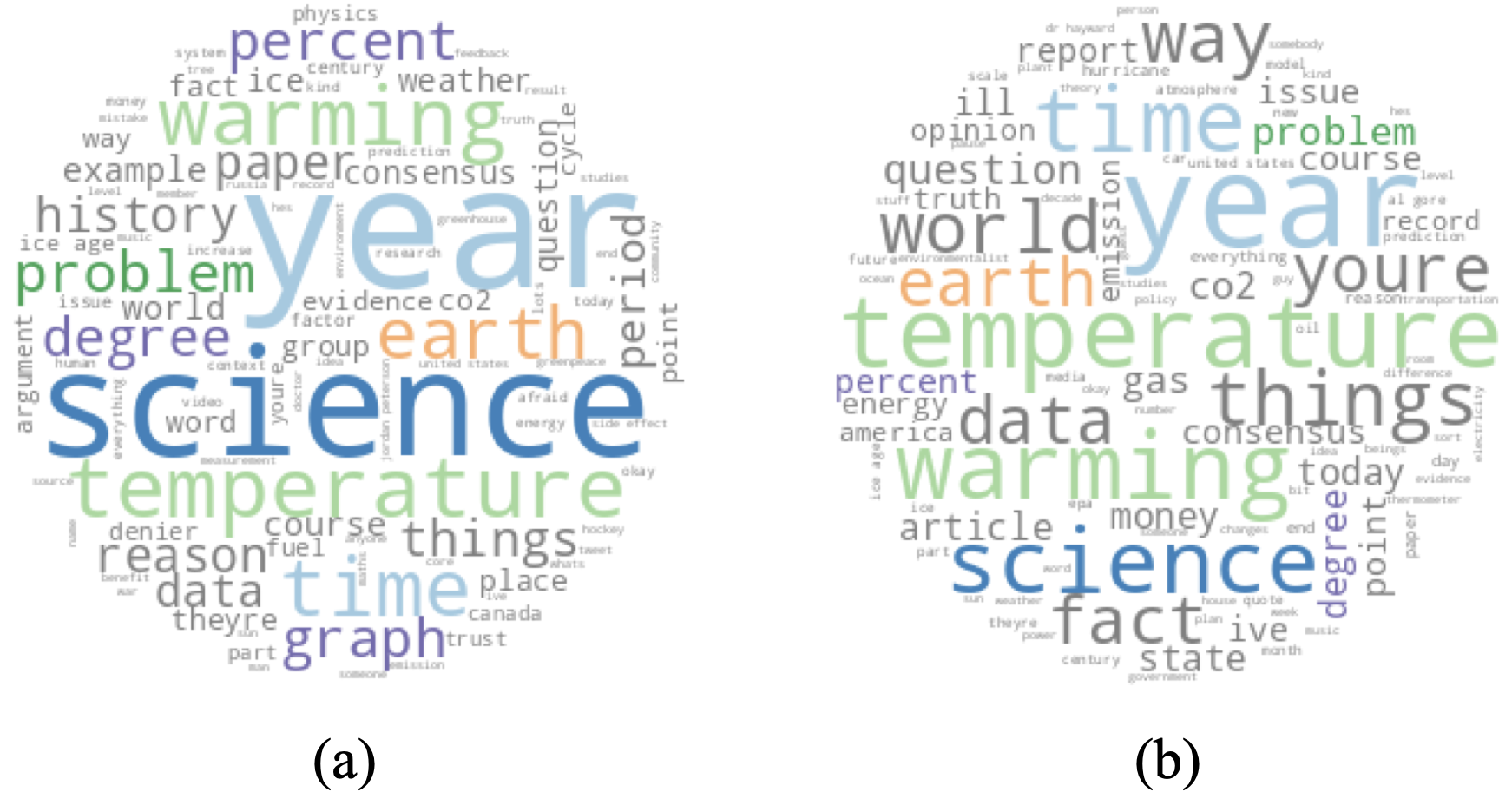
Public discourse around climate change remains polarized despite scientific consensus on anthropogenic climate change (ACC). This study examines how “believers” and “skeptics” of ACC differ in their YouTube comment discourse. We analyzed 44,989 comments from 30 videos using a large language model (LLM) as a qualitative annotator, identifying ten distinct topics. These annotations were combined with social network analysis to examine engagement patterns. A linear mixed-effects model showed that comments about government policy and natural cycles generated significantly lower interaction compared to misinformation, suggesting these topics are ideologically settled points within communities. These patterns reflect motivated reasoning, where users selectively engage with content that aligns with their identity and beliefs. Our findings highlight the utility of LLMs for large-scale qualitative analysis and highlight how climate discourse is shaped not only by content, but by underlying cognitive and ideological motivations.
@article{kim2025llm,title={LLM-Supported Content Analysis of Motivated Reasoning on Climate Change},author={Kim, Yuheun and Liu, Qiaoyi and Hemsley, Jeff},journal={Proceedings of the Association for Information Science and Technology},volume={62},number={1},pages={347--357},year={2025},publisher={Wiley Online Library}}
Scientists, but deny science? Climate change sceptics networks on YouTube led by scientists
Qiaoyi Liu, Yuheun Kim, and Jeff Hemsley
Information Research an international electronic journal 2025
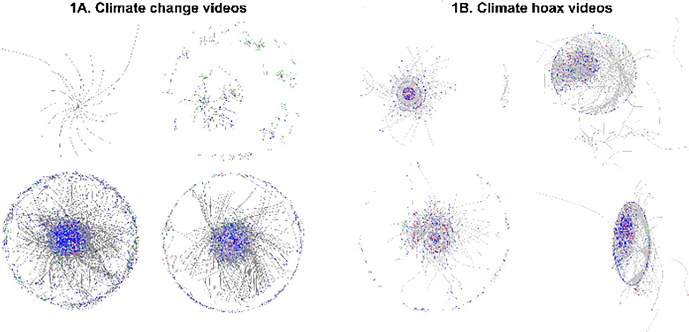
Introduction. Climate change debates have divided our society more than ever. Despite most scientists believing in anthropogenic climate change, a small group of people with scientific knowledge and reasoning are denying it. Method. In this paper, we collect YouTube video comments’ data to study the content posted by climate change sceptical scientists and their impact on comment social networks. Analysis. We apply natural language processing and social networks analyses to study those comments and networks. Results. We find that denying scientists question the validity of anthropogenic climate change using objective terms such as ‘Co2’, ‘history’, ‘data’, etc., while non-scientists rarely mention these terms, instead frequently using words like ‘money’, ‘truth’. Scientists-led social networks are also more structured with significant core users, while non-scientists-led networks have smaller and fragmented groups, indicating scientists-led discussions on climate change are more stable and consistent. Conclusions. Scientists who deny human-caused climate change cast greater influence on the climate change denying social networks. Their opinions using more scientific terms cause the networks to be more centralized and form more consistent patterns.
@article{liu2025scientists,title={Scientists, but deny science? Climate change sceptics networks on YouTube led by scientists},author={Liu, Qiaoyi and Kim, Yuheun and Hemsley, Jeff},journal={Information Research an international electronic journal},volume={30},number={iConf},pages={741--751},year={2025}}
2024
Climate Change Skeptics and the Power of Negativity
Qiaoyi Liu, Yuheun Kim, and Jeff Hemsley
Proceedings of the Association for Information Science and Technology 2024
Climate change is a polarized topic on social media in the U.S. Actors who advocate climate change as scientific fact, or tout it as a conspiracy, both post videos on YouTube. Both kinds of videos can receive millions of views and thousands of comments. Given the polarized nature of the topic, we might expect a high degree of vitriolic speech in the comments around the videos. Previous Twitter studies would also suggest significant differences in the networks made from the interactions of such comments and replies. This study focuses on these comments and replies in an effort to understand the nature of discourse surrounding climate change believer and skeptic videos. Our hope is to extend the existing literature studying scientific communication around climate change, which to our knowledge hasn’t specifically compared discussions around both climate change believers or skeptics on YouTube. Results show most users only comment on other users that align with their own perspectives about climate change, and express positive sentiment toward them. Our study also finds that the more negative the users’ comment, the more connections they have with other users. These findings indicate further investigations of climate change social activities on YouTube.
@article{liu2024climate,title={Climate Change Skeptics and the Power of Negativity},author={Liu, Qiaoyi and Kim, Yuheun and Hemsley, Jeff},journal={Proceedings of the Association for Information Science and Technology},volume={61},number={1},pages={999--1001},year={2024},publisher={Wiley Online Library}}
2023
Can ChatGPT Understand Causal Language in Science Claims?
Yuheun Kim, Lu Guo, Bei Yu, and Yingya Li
In Proceedings of the 13th Workshop on Computational Approaches to Subjectivity, Sentiment, & Social Media Analysis Jul 2023
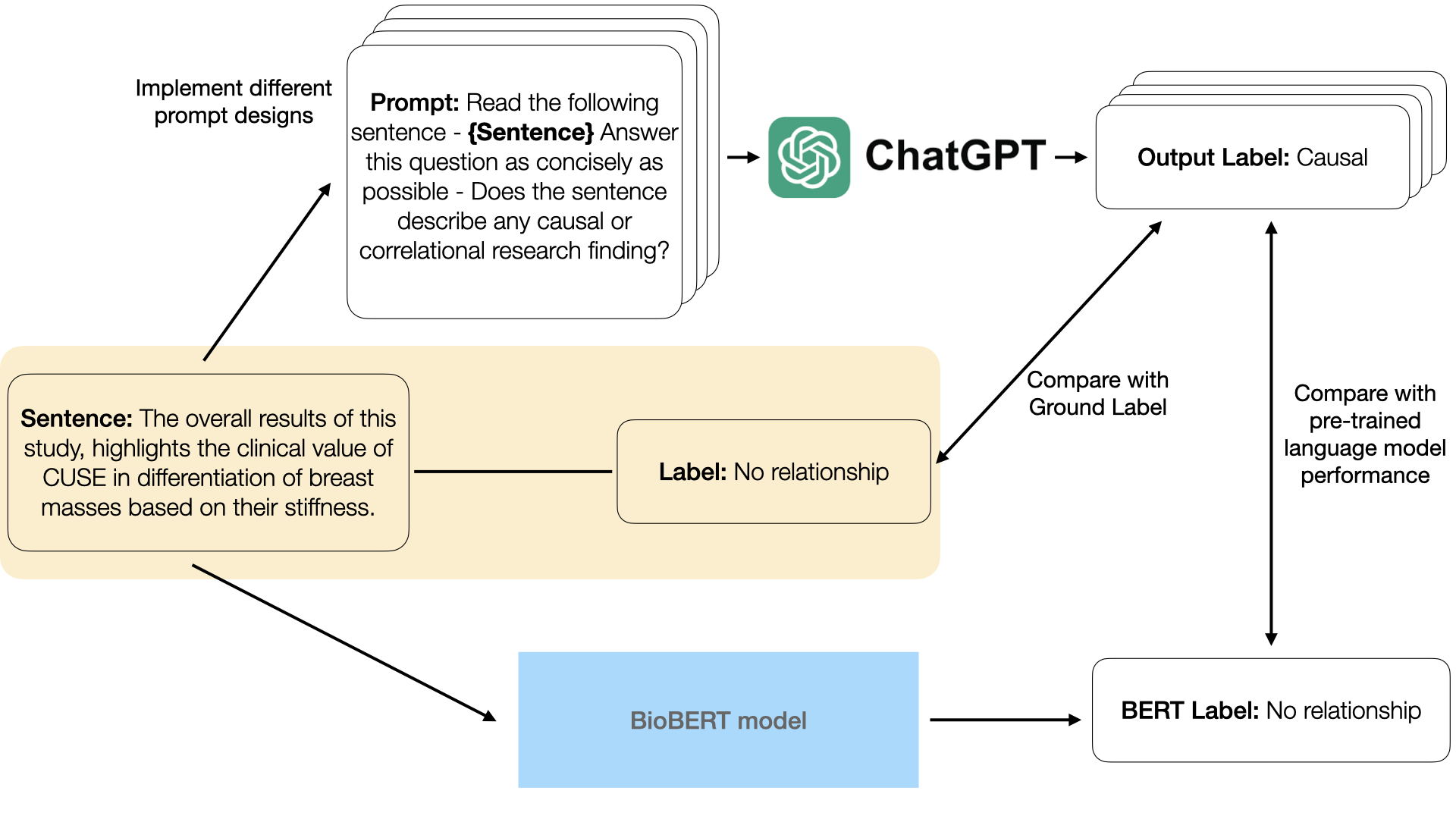
This study evaluated ChatGPT’s ability to understand causal language in science papers and news by testing its accuracy in a task of labeling the strength of a claim as causal, conditional causal, correlational, or no relationship. The results show that ChatGPT is still behind the existing fine-tuned BERT models by a large margin. ChatGPT also had difficulty understanding conditional causal claims mitigated by hedges. However, its weakness may be utilized to improve the clarity of human annotation guideline. Chain-of-Thoughts were faithful and helpful for improving prompt performance, but finding the optimal prompt is difficult with inconsistent results and the lack of effective method to establish cause-effect between prompts and outcomes, suggesting caution when generalizing prompt engineering results across tasks or models.
@inproceedings{2023-kim-chatgpt,title={Can {C}hat{GPT} Understand Causal Language in Science Claims?},author={Kim, Yuheun and Guo, Lu and Yu, Bei and Li, Yingya},booktitle={Proceedings of the 13th Workshop on Computational Approaches to Subjectivity, Sentiment, {\&} Social Media Analysis},month=jul,year={2023},address={Toronto, Canada},publisher={Association for Computational Linguistics},pages={379--389}}
2022
SQ2SV: Sequential Queries to Sequential Videos retrieval
Injin Paek, Nayoung Choi, Seongjin Ha, Yuheun Kim, and Min Song
In 2022 IEEE International Conference on Big Data (Big Data) Jul 2022
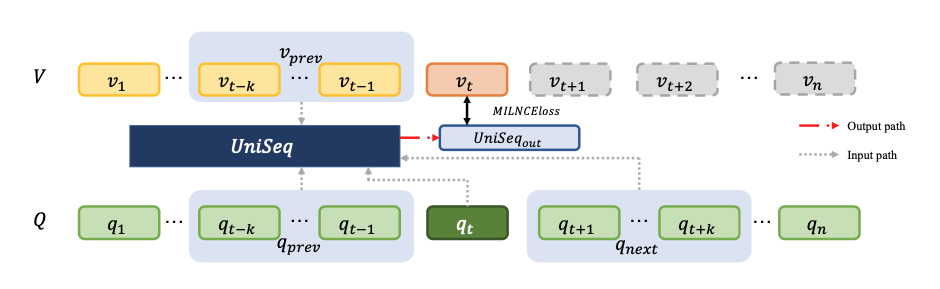
Current video retrieval models are one-to-one matching models, which limits them from learning from the sequential context of the videos. While most public datasets for this task are text-video pairs that are contextually independent, datasets such as YouCook2, Video Storytelling, and COIN consist of chronological text-video pair segments. This paper introduces a retrieval task Sequential Queries to Sequential Videos retrieval (SQ2SV) that retrieves multiple sets of sequential videos from sequential queries to utilize such contextual interdependence. To the best of our knowledge, this paper is the first a ttempt to introduce multiple sets of sequential videos retrieval. We not only introduce a new task but also build a task-specific model and its evaluation metric. Our model, UniSeq (UniVL-based sequential videos retrieval), is a sequential as well as a cross representation model. Our new metric ‘Video R@k’ evaluates the performance of a retrieval model in a unit of video, not in a unit of the video segment. Our best model outperforms the UniVL baseline in the original R@1 of YouCook2 by 0.40% and Video Storytelling by 1.09%. Furthermore, comparing the Video R@1 score, our model outperforms the baseline by 0.27% for YouCook2 and 0.94% for Video Storytelling.
@inproceedings{paek-2022-sq2sv,title={SQ2SV: Sequential Queries to Sequential Videos retrieval},author={Paek, Injin and Choi, Nayoung and Ha, Seongjin and Kim, Yuheun and Song, Min},booktitle={2022 IEEE International Conference on Big Data (Big Data)},volume={},pages={3631-3634},year={2022},doi={10.1109/BigData55660.2022.10020744}}
2021
BioPREP: Deep learning-based predicate classification with SemMedDB
Gibong Hong*, Yuheun Kim*, YeonJung Choi*, and Min Song
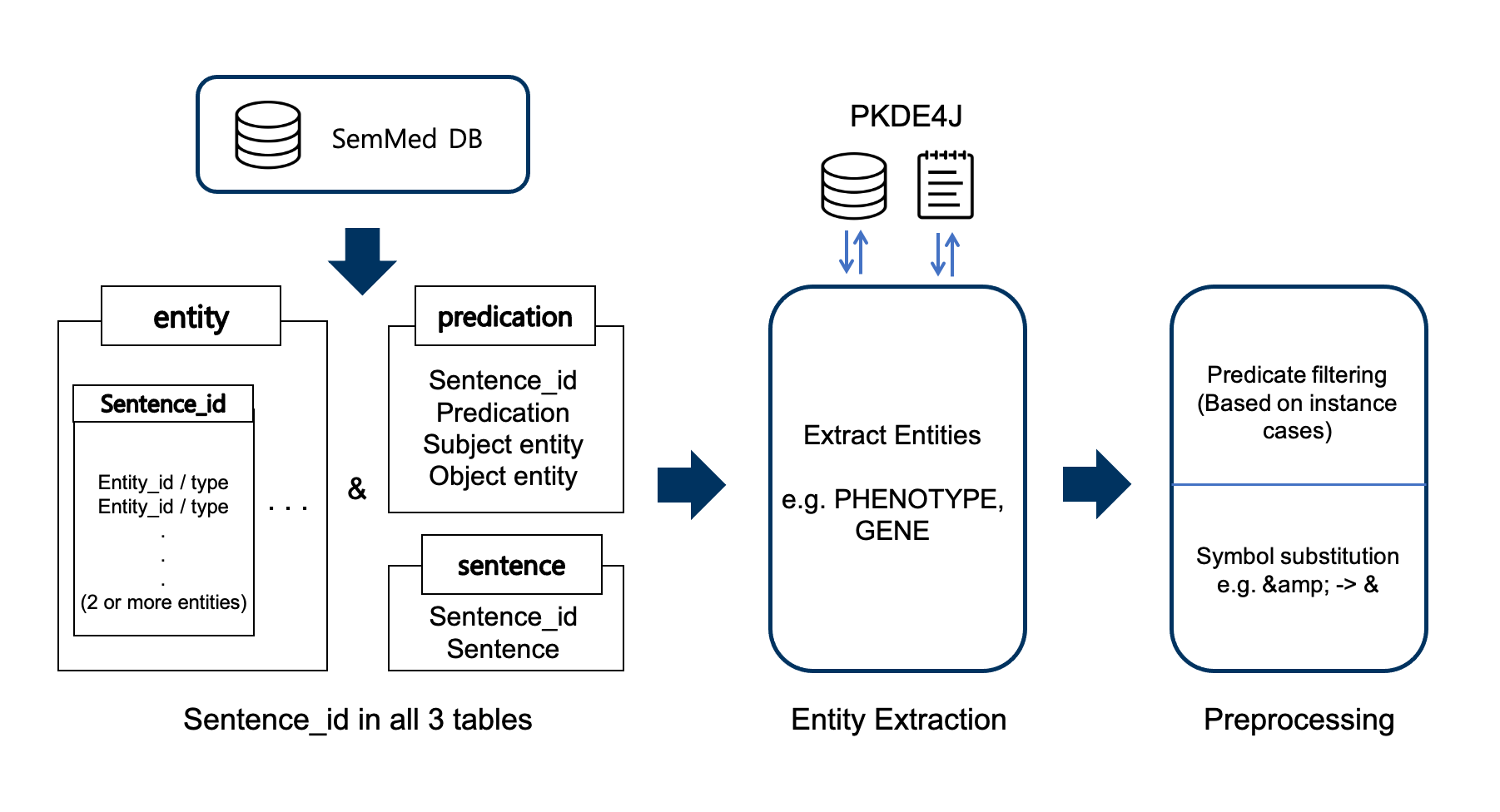
When it comes to inferring relations between entities in biomedical texts, Relation Extraction (RE) has become key to biomedical information extraction. Although previous studies focused on using rule-based and machine learning-based approaches, these methods lacked efficiency in terms of the demanding amount of feature processing while resulting in relatively low accuracy. Some existing biomedical relation extraction tools are based on neural networks. Nonetheless, they rarely analyze possible causes of the difference in accuracy among predicates. Also, there have not been enough biomedical datasets that were structured for predicate classification. With these regards, we set our research goals as follows: constructing a large-scale training dataset, namely Biomedical Predicate Relation-extraction with Entity-filtering by PKDE4J (BioPREP), based on SemMedDB then using PKDE4J as an entity-filtering tool, evaluating the performances of each neural network-based algorithms on the structured dataset. We then analyzed our model’s performance in-depth by grouping predicates into semantic clusters. Based on comprehensive experimental outcomes, the experiments showed that the BioBERT-based model outperformed other models for predicate classification. The suggested model achieved an f1-score of 0.846 when BioBERT was loaded as the pre-trained model and 0.840 when SciBERT weights were loaded. Moreover, the semantic cluster analysis showed that sentences containing key phrases were classified better, such as comparison verb + ‘than’.
@article{hong-2021-bioprep,title={BioPREP: Deep learning-based predicate classification with SemMedDB},author={Hong*, Gibong and Kim*, Yuheun and Choi*, YeonJung and Song, Min},journal={Journal of Biomedical Informatics},volume={122},pages={103888},year={2021},publisher={Elsevier}}