Yuheun Kim

📍 Syracuse NY, USA
Hello 👋, my name is pronounced as /Yeo-un/. I also go by Rachel so feel free to call me either. I am a PhD candidate in Syracuse University iSchool. My advisor is Joshua Introne.
My research sits at the intersection of Natural Language Processing (NLP), computational social science, and responsible AI. Specifically, my focus is on whether multilingual large language models are truly multilingual, not just in performance, but in how faithfully they represent the cultural knowledge embedded in the languages they process.
Check out my Google Scholar or CV for more information.
news
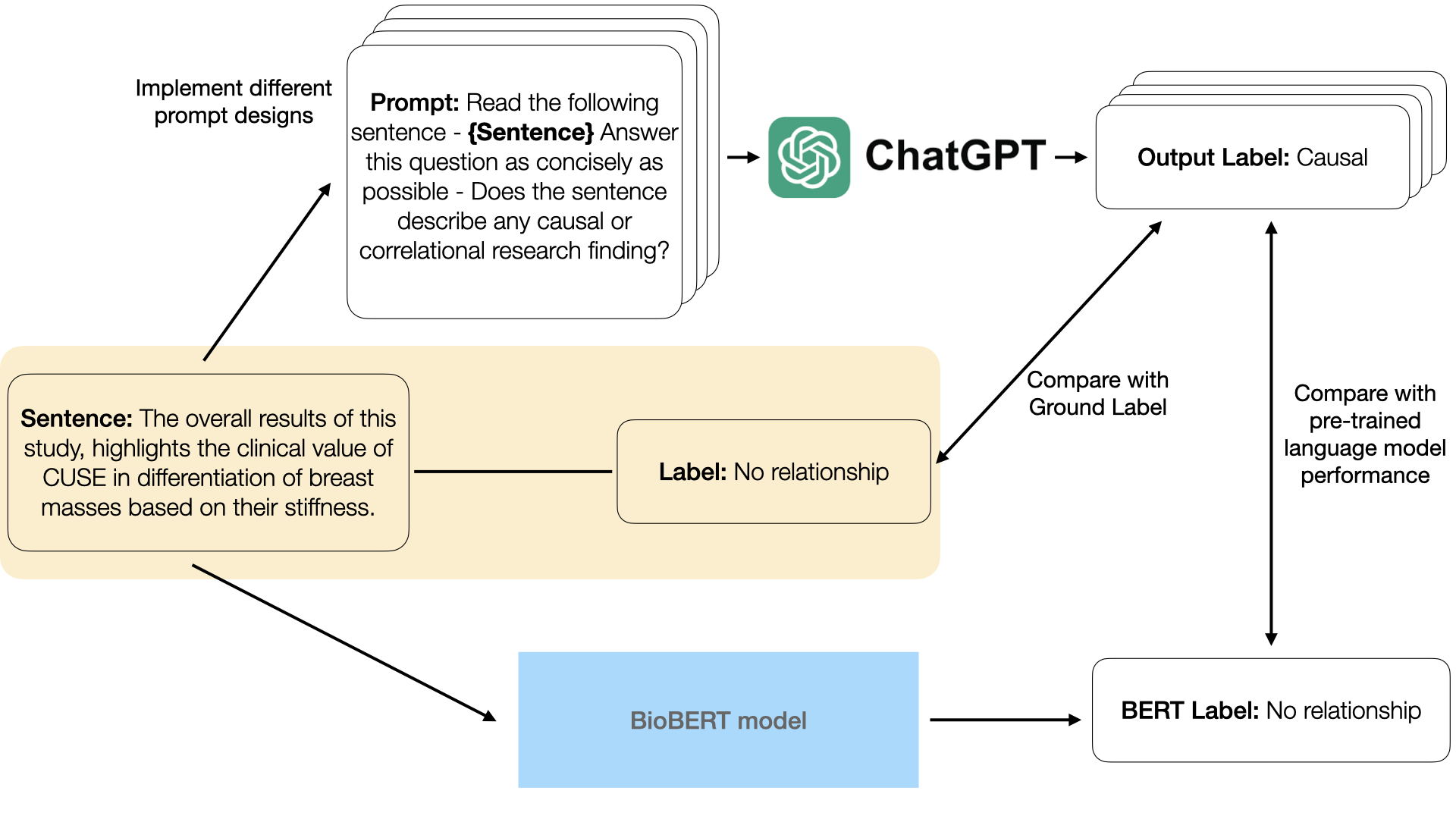
| May 20 | ✨ “LLM-Supported Content Analysis of Motivated Reasoning on Climate Change” [preprint] got accepted to ASIS&T 2025 for a virtual presentation. 🎉 |
|---|---|
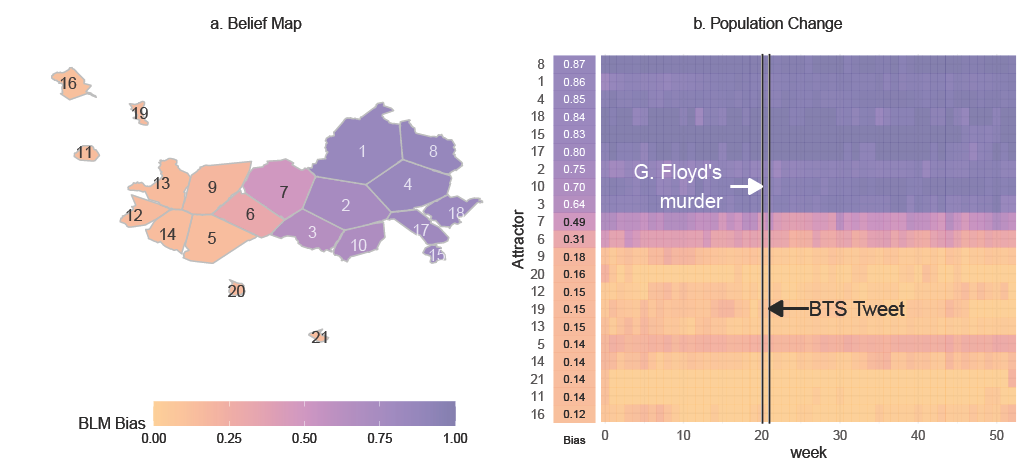
| Jul 15 | ✨ “Belief Alignment vs Opinion Leadership: Understanding Cross-linguistic Digital Activism in K-pop and BLM Communities” [preprint] got accepted to ICWSM 2026! 🎉 |